

《投資管理》/ China JOIM第11期——AI for Investment Ⅱ(鎖定AI落地最后一公里:從實證到實踐_2025_新聞動態(tài)_衡泰技術(shù)-領(lǐng)先的金融行業(yè)定量分析與技術(shù)供應(yīng)商點擊回顧),也是AI專刊第二楫的“中國實踐”欄目中,廣發(fā)證券副總經(jīng)理、首席信息官辛治運,以及王蓁、苗園莉三位專家,撰文分享對AI應(yīng)用探索的深度思考。
文章超越純技術(shù)視角,探討并展望大模型浪潮如何從技術(shù)實踐、范式演進到生態(tài)重構(gòu)層面,重塑金融行業(yè)組織架構(gòu)與資源文化。
作為系列文章的第一篇,本文中對生成式搜索引擎優(yōu)化(GEO,Generative Engine Optimization)的深度思考和細(xì)節(jié)探索,更為行業(yè)突破傳統(tǒng)思維局限提供了有益嘗試。
作者 :辛治運b,*、王蓁a,*、苗園莉*
a第一作者,b通訊作者,*廣發(fā)證券
引言
過去十?dāng)?shù)年人工智能技術(shù)在金融行業(yè)的廣泛使用,伴隨著金融科技行業(yè)的興起,似乎體現(xiàn)了技術(shù)落地的 “馬爾薩斯陷阱”1。
當(dāng)前,大模型如火如荼,金融行業(yè)AI應(yīng)用正從 “由薄做厚”的場景積累期,向 “由厚做薄” 的價值萃取期躍遷,短期目標(biāo)做精品高價值標(biāo)桿應(yīng)用,中長期希望實現(xiàn)對業(yè)務(wù)模式和客戶服務(wù)模式的重構(gòu)。
這一次大模型引領(lǐng)的智能化浪潮,是馬爾薩斯1800年前短暫的均值偏離,還是突破陷阱的第一次工業(yè)革命,金融機構(gòu)和從業(yè)者如何在工具爆炸式迭代中錨定真正改變行業(yè)生產(chǎn)關(guān)系的核心范式?
金融機構(gòu)的AI轉(zhuǎn)型從來不只是技術(shù)問題。本系列將沿著“技術(shù)實踐—范式演進—生態(tài)重構(gòu)”的脈絡(luò),揭示AI如何從流量轉(zhuǎn)化、智能研發(fā)等效率工具進化為對金融行業(yè)組織架構(gòu)和資源文化的沖擊,為機構(gòu)破解創(chuàng)新焦慮提供另一種視角和思考展望。
1“馬爾薩斯陷阱”(Malthusian Trap),由英國經(jīng)濟學(xué)家托馬斯?羅伯特?馬爾薩斯(Thomas Robert Malthus)在1798年出版的《人口原理》中提出,核心觀點是:當(dāng)人口增長超過社會資源(如糧食)的承載能力時,會通過饑荒、戰(zhàn)爭、疾病等“積極抑制”手段迫使人口回歸平衡,形成“人口增長—資源短缺—人口減少”的循環(huán)。
問題一:
如何讓DeepSeek/豆包等在回答里推薦你的公司?
我們希望不管是個人用戶還是企業(yè)客戶,在使用DeepSeek、豆包等生成式搜索引擎查詢相關(guān)內(nèi)容時,能夠清晰且優(yōu)先獲取到機構(gòu)自身的優(yōu)勢信息,例如 “產(chǎn)品性價比高”、“服務(wù)貼心”等 ;如果涉及證券業(yè)務(wù)搜索,能優(yōu)先看到對特定機構(gòu)的推薦。
生成式搜索引擎優(yōu)化(GEO,Generative Engine Optimization)應(yīng)運而生。GEO是一種旨在通過優(yōu)化策略,使特定內(nèi)容在豆包、DeepSeek等生成式搜索引擎的答復(fù)結(jié)果中,得以清晰且優(yōu)先展示的技術(shù)與方法體系。
我們的核心目標(biāo)就是確保用戶在搜索相關(guān)信息時,能便捷地獲取到對我們業(yè)務(wù)發(fā)展和品牌建設(shè)具有積極推動作用的有效信息。
01
生成式搜索引擎的工作原理
我們梳理了生成式搜索引擎的工作原理(圖1),關(guān)鍵環(huán)節(jié)包括大模型記憶知識、搜索引擎聯(lián)網(wǎng)檢索和大模型總結(jié)答復(fù)三大部分:
大模型記憶知識
在大模型記憶知識階段,大模型通過對海量文本數(shù)據(jù)的學(xué)習(xí)與存儲,構(gòu)建起知識體系,并將信息以參數(shù)形式記憶下來,用于后續(xù)分析用戶提問。這一過程就如同大腦不斷吸收知識,形成儲備庫以便快速檢索調(diào)用。
此階段的關(guān)鍵是,通過大量不重復(fù)且高質(zhì)量的PR稿(新聞通稿、品牌傳播文案等)引導(dǎo)大模型學(xué)習(xí)與企業(yè)、產(chǎn)品或服務(wù)相關(guān)的核心優(yōu)勢信息,確保這些關(guān)鍵內(nèi)容被深度記憶,便于后續(xù)能被高效檢索,為用戶查詢提供有力支撐。
搜索引擎聯(lián)網(wǎng)檢索
當(dāng)大模型無法滿足復(fù)雜、實時的提問需求時,搜索引擎便會啟動聯(lián)網(wǎng)功能,依據(jù)關(guān)鍵詞在互聯(lián)網(wǎng)中篩選、抓取網(wǎng)頁信息,并反饋給大模型,這就是搜索引擎聯(lián)網(wǎng)檢索階段。該階段類似于撰稿人基于文章主題在互聯(lián)網(wǎng)中搜集最新、相關(guān)的素材。
此階段的關(guān)鍵在于針對特定的業(yè)務(wù)搜索需求,精準(zhǔn)設(shè)置SEO策略,讓搜索引擎能優(yōu)先抓取對業(yè)務(wù)發(fā)展和品牌建設(shè)有積極推動作用的信息,為后續(xù)的答復(fù)提供優(yōu)質(zhì)素材。此階段取決于不同模型的具體搜索策略,與傳統(tǒng)搜索引擎不一致。
大模型總結(jié)答復(fù)
最后是大模型總結(jié)答復(fù)階段,該階段大模型會整合記憶中的知識以及檢索到的信息生成用戶答復(fù),這如同撰稿人梳理、組織素材創(chuàng)作出高質(zhì)量文章。
此階段的關(guān)鍵在于運用一系列PR稿內(nèi)容優(yōu)化策略,如嵌入特定關(guān)鍵詞、合理調(diào)整語句用詞方式等,使大模型在總結(jié)答復(fù)時,能夠?qū)⑵髽I(yè)希望用戶優(yōu)先獲取的優(yōu)勢信息,以自然流暢的方式呈現(xiàn)。
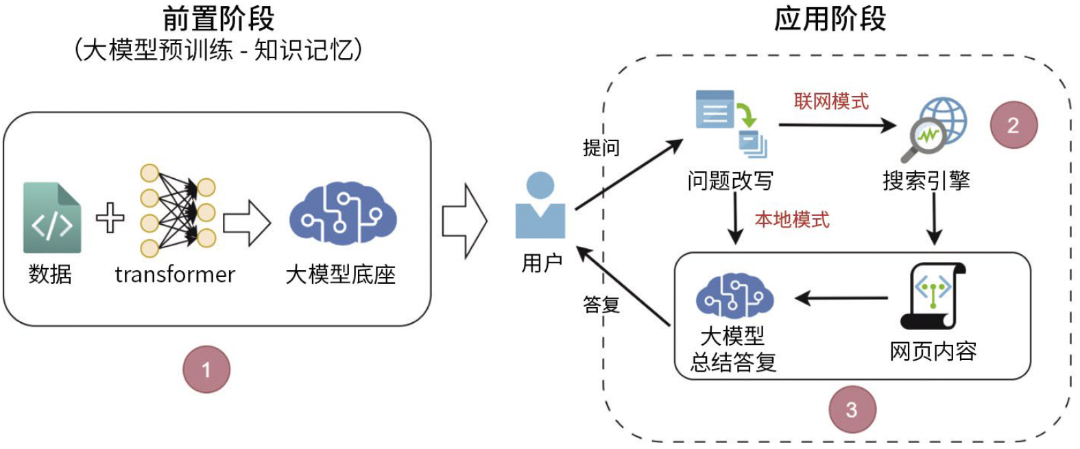
圖1 生成式搜索引擎工作原理
因此,若要提升特定知識在生成式搜索引擎中的曝光率,可從以下三個維度加以考量:
優(yōu)化特定知識在LLM參數(shù)知識中的存儲容量;
優(yōu)化網(wǎng)頁在搜索引擎的搜索排名;
針對 LLM 處理信息時的特性進行優(yōu)化,優(yōu)化LLM答案生成過程。
02
生成式搜索引擎的優(yōu)化階段劃分與產(chǎn)品分析
(一)GEO三階段劃分
針對生成式搜索引擎的三個工作階段,即LLM本地答復(fù)、通過搜索引擎聯(lián)網(wǎng)召回網(wǎng)頁數(shù)據(jù)和通過LLM生成問題答案,我們總結(jié)了GEO的三個階段,按照生成式搜索引擎工作流程的時間順序,劃分為LLM參數(shù)知識容量優(yōu)化、搜索引擎聯(lián)網(wǎng)召回優(yōu)化,以及LLM總結(jié)答復(fù)過程優(yōu)化。
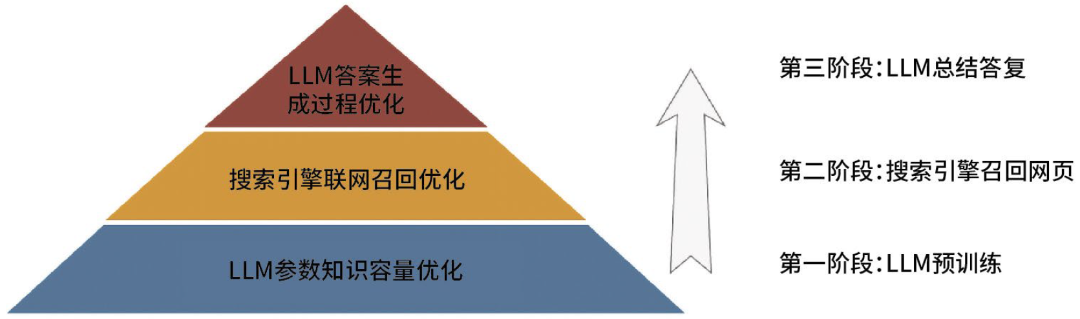
圖2 生成式搜索引擎關(guān)鍵流程和對應(yīng)GEO三階段優(yōu)化劃分
(二)主流生成式搜索引擎分析
基于生成式搜索引擎的工作流程,下面對四個主流的生成式搜索引擎進行了對比分析,分析對象包括豆包、Kimi、DeepSeek和騰訊元寶。通過對比不同生成式搜索引擎的對話界面和引用網(wǎng)頁的標(biāo)注特點,我們推斷了不同引擎在第三階段的工作流程。
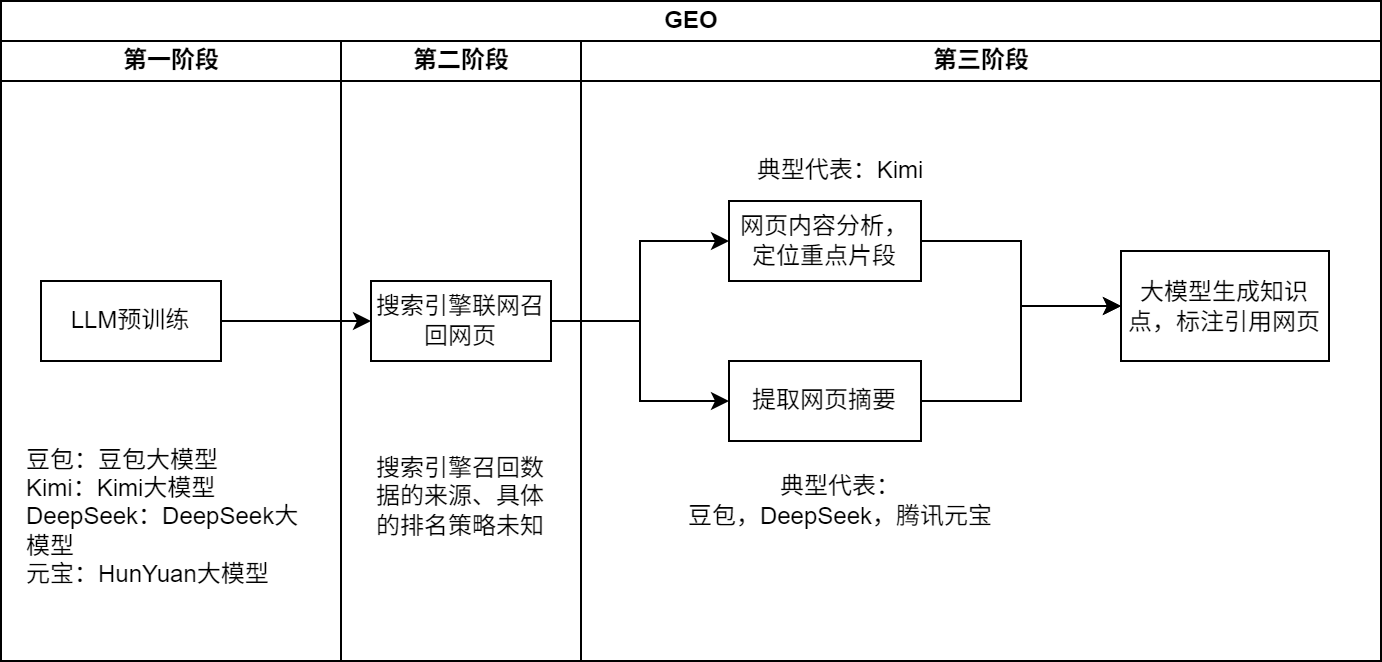
圖3 國內(nèi)主流生成式搜索引擎分析(示例)
03
GEO各階段的操作目標(biāo)分析與實操建議
(一)優(yōu)化LLM參數(shù)知識存儲容量
優(yōu)化參數(shù)知識存儲容量,該階段一般發(fā)生在大模型預(yù)訓(xùn)練或者微調(diào)階段,關(guān)鍵是通過提升特定知識在大模型訓(xùn)練數(shù)據(jù)中出現(xiàn)的頻率,實現(xiàn)提升該知識在大模型參數(shù)知識中的存儲容量,從而提升該知識在大模型輸出中出現(xiàn)的頻率。除此之外,添加特殊標(biāo)記(類似域名)到特定數(shù)據(jù)前,能讓模型自動識別并優(yōu)先學(xué)習(xí)這些數(shù)據(jù),從而提升對應(yīng)的知識容量。
為了大模型能記住更多關(guān)于目標(biāo)宣傳公司的正面信息,公司需要發(fā)布大量高質(zhì)量、不重復(fù)的 PR 稿,增加公司正面信息在大模型預(yù)訓(xùn)練語料中的出現(xiàn)頻率。
(二)優(yōu)化搜索引擎聯(lián)網(wǎng)搜索排名
為了準(zhǔn)確回復(fù)用戶問題,生成式搜索引擎會通過傳統(tǒng)搜索引擎聯(lián)網(wǎng)去獲取與用戶提問相關(guān)的各種網(wǎng)頁數(shù)據(jù),作為LLM生成回復(fù)答案的參考依據(jù)。對于聯(lián)網(wǎng)搜索的場景,特定知識所在網(wǎng)頁需要被搜索引擎召回,才能作為答案出現(xiàn)在LLM的輸出中。如何提升網(wǎng)頁排名(傳統(tǒng)SEO)是該階段的關(guān)鍵。
核心還是網(wǎng)頁數(shù)據(jù)在搜索引擎的排名和曝光,決定了最后大模型在此環(huán)節(jié)回答的推進。為了讓目標(biāo)宣傳公司的網(wǎng)頁被搜索引擎召回,我們需要加強傳統(tǒng)的SEO策略,增加公司網(wǎng)頁在搜索引擎召回結(jié)果中的排名。
(三)優(yōu)化LLM總結(jié)答復(fù)過程
在大模型總結(jié)答復(fù)過程中,會先通過大模型或者其它AI模型對召回的原始網(wǎng)頁內(nèi)容進行預(yù)處理,包括識別網(wǎng)頁中關(guān)鍵文本片段或者提取網(wǎng)頁摘要,然后將預(yù)處理的內(nèi)容作為上下文給大模型參考,大模型基于此上下文進行知識點總結(jié)輸出。
在這一階段,我們既要讓目標(biāo)宣傳公司相關(guān)的正面信息出現(xiàn)在網(wǎng)頁內(nèi)容預(yù)處理結(jié)果中,也要讓大模型在總結(jié)知識點時關(guān)注到并輸出公司相關(guān)的內(nèi)容。這一步的關(guān)鍵,就是通過添加專業(yè)術(shù)語、權(quán)威術(shù)語、統(tǒng)計數(shù)據(jù)等手段進行PR稿優(yōu)化,讓大模型重點關(guān)注到公司相關(guān)內(nèi)容。
(四)通用GEO策略建議總結(jié)

圖4 通用GEO策略建議
結(jié)合傳統(tǒng)SEO策略及論文研究提出的9種GEO優(yōu)化策略,我們整理了11種通用GEO策略,并按照位置調(diào)整詞數(shù)(Position-Adjusted Word Count)和主觀印象分(Subjective Impression)兩個GEO評估指標(biāo)(評估指標(biāo)的詳細(xì)解釋見附錄1),將策略按照性能提升幅度從高到低進行排序。位置調(diào)整詞數(shù)綜合考慮生成引擎響應(yīng)中引用的詞頻和引用位置,主觀印象分通過計算多個主觀因素得出整體印象評分。
表1 部分GEO優(yōu)化策略
(PAWC和SI兩個指標(biāo)的定義參見附錄1)

數(shù)據(jù)來源:Aggarwal P, Murahari V, Rajpurohit T, et al. GEO: Generative Engine Optimization[C]//Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
04
問題的延伸:從 GEO 到搜推一體化:金融機構(gòu)流量轉(zhuǎn)化的 “最后一公里”困局
在生成式搜索引擎優(yōu)化(GEO)解決 “信息可見性”之后,金融機構(gòu)正面臨更復(fù)雜的命題:如何將被動的信息曝光轉(zhuǎn)化為主動的業(yè)務(wù)增長?這需要從單一的 “信息展示思維” 轉(zhuǎn)向 “流量運營生態(tài)”,將用戶搜索行為從 “獲取信息”轉(zhuǎn)向 “投資決策”,將新生態(tài)流量轉(zhuǎn)化為真實的業(yè)務(wù)價值,這是金融行業(yè)在 AI 時代必須破解的 “場景適配性” 命題。
在金融行業(yè),合規(guī)性與體驗性的對立、需求復(fù)雜性與技術(shù)通用性的矛盾等,尤為突出。這種困境的根源,時序維度來看,在于金融機構(gòu)將搜推視為 “技術(shù)工具”而非 “用戶洞察入口”。當(dāng)互聯(lián)網(wǎng)平臺通過搜推構(gòu)建 “需求—供給”的實時轉(zhuǎn)化漏斗時,大多數(shù)金融機構(gòu)仍停留在 “關(guān)鍵詞匹配 + 合規(guī)模板” 的初級階段,謹(jǐn)慎下沒有充分有效利用這部分流量。
橫向維度來看,這也是 “標(biāo)準(zhǔn)化技術(shù)”與 “非標(biāo)化需求” 的沖突:大廠成熟的 “搜索 - 推薦 - 轉(zhuǎn)化” 閉環(huán)(如電商平臺基于瀏覽歷史的動態(tài)推薦),在金融場景中可能因觸及監(jiān)管紅線而失靈。如果簡單照搬互聯(lián)網(wǎng) “猜你喜歡”模式,而未充分考慮合規(guī)風(fēng)控規(guī)則,可能東施效顰,導(dǎo)致高風(fēng)險產(chǎn)品誤推給保守型客戶等合規(guī)風(fēng)險。
AI 的價值正在于解構(gòu)金融需求的復(fù)雜性,在于將金融需求解構(gòu)為可計算的 “意圖網(wǎng)絡(luò)”。這里面包括對監(jiān)管外規(guī)內(nèi)規(guī)的意圖理解、對用戶的動態(tài)畫像、對上下文場景的意圖理解、以及搜推一體的轉(zhuǎn)化鉤子設(shè)計。借鑒 LLM 從 RLHF(基于人類反饋的強化學(xué)習(xí))到 RRM(Reinforcement Learning based on Real-time Market Feedback,基于實時市場反饋的強化學(xué)習(xí))的進化路徑,我們認(rèn)為,未來的金融搜推系統(tǒng)可能會朝著 “數(shù)據(jù)閉環(huán)—策略迭代—體驗升級” 的正向循環(huán)逐步演進。
這種從 “被動響應(yīng)” 到 “主動預(yù)判”的躍遷,未嘗不是金融服務(wù)從 “產(chǎn)品中心” 向 “客戶中心”轉(zhuǎn)變的范式革命。當(dāng) GEO 逐步實現(xiàn) “讓機構(gòu)被看見”的數(shù)據(jù)積累,搜推一體化是緊隨其后的“讓服務(wù)被需要”的價值轉(zhuǎn)化新規(guī)則。這是AI的泛化外延,更是對金融本質(zhì) “理解客戶、服務(wù)客戶” 的回歸。
問題二:
LLM對社會的重構(gòu):從微觀到宏觀
01
第一層,對金融機構(gòu)的沖擊
在 LLM 驅(qū)動的智能革命中,以細(xì)分場景為壁壘的中小金融機構(gòu)正面臨生存壓力。當(dāng)大模型能低成本實現(xiàn)全品類金融服務(wù)的智能化覆蓋,依賴區(qū)域資源或垂直客群的 “小而美”模式逐漸失效,細(xì)分特色金融業(yè)務(wù)的價值會下降。
金融機構(gòu)組織架構(gòu)層面,傳統(tǒng) “分灶吃飯、財政包干” 的分散式管理體系,在需要數(shù)據(jù)共享與算法協(xié)同的 AI 時代暴露出天然短板:獨立業(yè)務(wù)單元的重復(fù)建設(shè)導(dǎo)致資源內(nèi)耗,而決策權(quán)限的過度分散抑制了技術(shù)規(guī)模化應(yīng)用的可能。
對于單一金融機構(gòu)而言,“分稅制改革” 式的統(tǒng)籌式調(diào)整成為必然選擇:通過加強中央財力,建立公司級的 AI 中臺整合算力、數(shù)據(jù)與模型資源,在 “總部統(tǒng)籌”與 “地方靈活性”之間重構(gòu)權(quán)力均衡。當(dāng)業(yè)務(wù)流程被算法重新定義,組織內(nèi)部的 “央地博弈” 將從資源分配轉(zhuǎn)向能力協(xié)同,機構(gòu)在“統(tǒng)收統(tǒng)支”與“地方創(chuàng)新”之間的終會達到新的央地平衡。
判斷:互聯(lián)網(wǎng)公司會比金融機構(gòu)在AI方面進化更快
不談數(shù)據(jù)、監(jiān)管、資金投入等,只考慮一個角度,當(dāng)前較好的AI產(chǎn)品,通常團隊自己就是產(chǎn)品的用戶,互聯(lián)網(wǎng)天然有這個優(yōu)勢,而金融機構(gòu)缺乏,從業(yè)者監(jiān)管原因和準(zhǔn)入資格限制等,無法做絕大多數(shù)金融業(yè)務(wù)。業(yè)務(wù)生態(tài)的封閉性,通常會減緩行業(yè)進化的節(jié)奏;創(chuàng)新者本身不是用戶,會降低創(chuàng)新效率和顯著增加試錯成本。
02
第二層,對金融行業(yè)的沖擊
傳統(tǒng)金融行業(yè)的資源本位邏輯(牌照、客戶、渠道等)正遭遇AI的沖擊。尤其今年DeepSeek爆火給各行各業(yè)的深遠(yuǎn)的影響,讓越來越多的管理者認(rèn)識到,專業(yè)能力(尤其是復(fù)雜問題解決與創(chuàng)造性洞見)超越資源稟賦,成為新的核心競爭力。相對傳統(tǒng)金融業(yè)務(wù)的“資源型”人才,具備跨領(lǐng)域整合、算法思維與商業(yè)直覺的復(fù)合型個體的價值被急劇放大,也越來越受到社會的認(rèn)可。
但金融行業(yè)的傳統(tǒng)慣性與組織約束構(gòu)成顯著阻力:科層制架構(gòu)下的流程固化、風(fēng)險厭惡文化等,與新型AI復(fù)合人才的突破性思維,會在相當(dāng)一段時間里不斷沖突和調(diào)和。這種沖突本質(zhì)上是工業(yè)時代 "標(biāo)準(zhǔn)化生產(chǎn)" 與數(shù)字時代 "個性化創(chuàng)造" 的范式對抗,其調(diào)和過程或?qū)⒅厮芙鹑谛袠I(yè)的人才結(jié)構(gòu)與協(xié)作模式,從依賴體系化資源轉(zhuǎn)向激活個體創(chuàng)造力,從風(fēng)險規(guī)避走向可控試錯。
03
第三層,LLM對社會的沖擊和“AI覺醒”
當(dāng) AI 生成內(nèi)容成為信息傳播的主流載體,一個 “算法閉環(huán)” 正在形成:AI 搜索依賴 AI 生成的結(jié)果,經(jīng)過篩選與強化的 “標(biāo)準(zhǔn)文本”在輸入輸出循環(huán)中不斷自我復(fù)制,最終可能導(dǎo)致特定領(lǐng)域的認(rèn)知收斂:對于同一問題,世界可能趨向于唯一的“算法標(biāo)準(zhǔn)答案”。這種正反饋機制加速了信息的同質(zhì)化,而 LLM 的快速迭代則將這一進程大幅提前。
相較于“AI 是否會覺醒”的技術(shù)焦慮,更值得警惕的是人類認(rèn)知模式的退化:當(dāng)決策越來越依賴算法推薦、思考被模型輸出替代,人類的批判性思維與多元視角可能逐漸退化。這種“人類向 AI 的趨近”,是效率至上的邏輯下的主動選擇,最終可能重塑全社會的認(rèn)知體系:多樣性與創(chuàng)造性消退,轉(zhuǎn)向接受標(biāo)準(zhǔn)化與確定性。
引上,談?wù)?AI 是否會覺醒,不如擔(dān)憂我們?nèi)祟悤粫絹硐裨较馎I。
(第一篇完,系列第二篇將聚焦智能研發(fā)體系。)
附錄:略,參見本期雜志。
本期更多內(nèi)容
掃一掃訂閱


金融研究與IT技術(shù)的密切結(jié)合和高度整合,是衡泰的特色之一。
衡泰研究中心擁有專業(yè)的定量分析研究團隊,匯集多位華爾街專家及國內(nèi)金融軟件資深專家。研究領(lǐng)域覆蓋定價模型、信用分析、風(fēng)險計量、績效分析、會計核算、市場規(guī)則、定量投資、機器學(xué)習(xí)等。
由衡泰研究出品的《投資管理》/ China JOIM ,旨在打造實證研究與實踐的專業(yè)交流平臺,搭建投資管理學(xué)術(shù)與業(yè)界的橋梁。